PDF OCR with Tesseract
Let there be search!
I've just been assigned another 150 PDF pages for the weekend. Printing on campus is 7¢ per page. You might say to yourself, "Well, it's only $10." That's what I said to myself the first week of the semester, and the second, and the third. Until it hit me: there are a lot of weeks between now and getting a PhD. I'm going to spend hundreds of dollars printing pages I will not be able to file in my tiny, overpriced studio apaprtment (one closet is already entirely full of books). And I've got other expenses—medical, technological, and transportational. So I don't print. Even though some studies show that reading on paper results in greater learning. I let my learning comprehension take it in the gut to save my pocketbook. I've got to afford that tango lesson / week's worth of groceries / tank of gas.
So I won't print. That's ok. Still do-able . I sit down with my handy and egregiously expensive eReader or laptop in my favorite chair, ready to crank away at some reading assignments. I open up the PDF in, say OS X Preview or another PDF reader. I read for a bit. I find a passage I like. "Gee," I say to myself, "I'd like to highlight that passage." I drag the old cursor to the passage in question, click, drag, and... Pfft, the entire page is selected.
What's happening? Usually, when scanning a document with high-quality scanning software, there is an option to scan with OCR. OCR stands for Optical Character Recognition. If you've seen the option to create a "searchable PDF" on a library scanner, that's idiot-speak for "scan with OCR." OCR technology recognizes the characters and layout in a scanned document and makes those characters recognizable to other computer applications. If you don't scan a document with OCR, it doesn't have OCR. All the letters in the document are just pixels of various colors in what is, for all intents and purposes, a bunch of image files strung together in what is now an utterly blackboxed imitation of paper pages. You can still read the pixels on a screen, but you cannot select, copy, search, or highlight any of the text in the PDF.
Sound useless? It is.
Not, of course, useless if you're going to print every page that you read for every class. And I am embarrassed to report that, after a year in a graduate program in the year of 2015, despite the fact that everyone's bag is festooned with the latest iPhone, despite the fact that digital devices are so common there are special e-waste recycling bins on campus, and despite the fact that we show up week after week to seminar with laptops and iPads which litter the tables and interject the occasional and unmistakable pop or ping or jingle of a messaging app notification into otherwise erudite discussion, my professors still think I print every page they assign. We are encouraged at every turn to digitize our notes and annotations, to archive, archive, archive, and to use electronic bibliography managers. But where the rubber hits the road, where individual reading assignments are assigned and distributed, approximately 50% of the digital files I receive do not have OCR and are therefore effectively useless for any sort of digital notetaking or reuse. In fact, because these files cannot be annotated at all, they are more useless than printed paper.
My original solution was an aging installation of Adobe Acrobat Professional on the Macbook Pro I use for programming. Acrobat has an OCR option in its menus. You open the file, select the OCR option, and let it chew away at your file. (OCR is slow. It takes a while to munch through a page. It would take you a while to identify and record every letter on a page of print.) Unfortunately, what I found was that Acrobat's OCR tends to fail silently on big files. I could get through the first 10 pages, then run it again for the next 10 pages, then again for the next 10. Sound maddening? Even more so when you've still got 200 pages to read for the night.
So what's the solution? What's the (ideally) low- or no-cost, open-source or at least non-proprietary solution? Tesseract.
Tesseract's documentation looked straightforward enough, and I had extraction of text to a .txt file working immediately. But I really, really struggled with conversion from .tif to .pdf. Ryan Bauman's blog post helped me get tesseract up and running from homebrew. I'm not sure, but I think the important difference was installing the dev version of tesseract. Don't be afraid of the command line. It will give you superpowers!!
Once this installation is complete, and you're able to get data out of tesseract...
As-MacBook-Air:~ macair$ tesseract --version
tesseract 3.03
leptonica-1.72
libjpeg 8d : libpng 1.6.18 : libtiff 4.0.4 : zlib 1.2.5
then you can begin the conversion process.
The first step is not with tesseract but with OS X Preview. Tesseract takes .tiff input. Open the non-OCR PDF in Preview. Select File > Export.... On the subsequent screen, select TIFF for the Format option. Select Save.
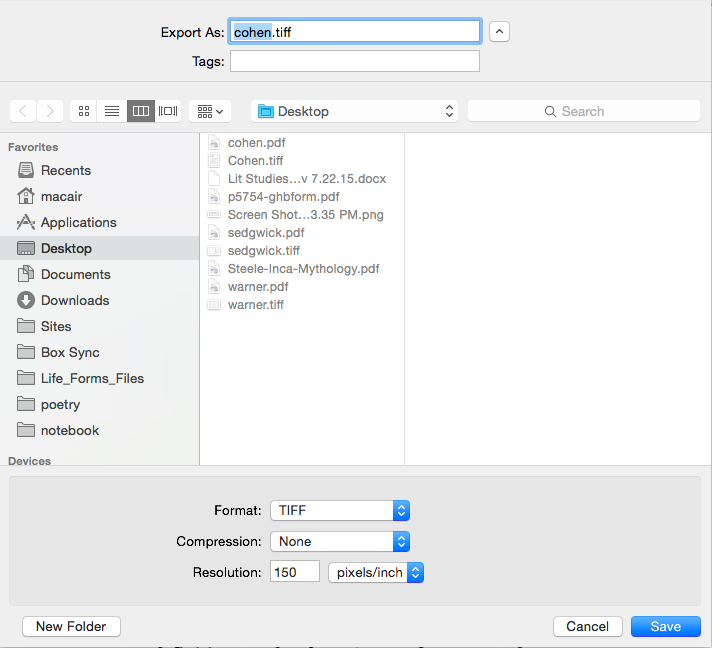
Now you've got a .tiff file consisting of several "page" images (just as useless and pretty as the original PDF). Open the file up and make sure things look peachy. Now it's time for tesseract magic:
cd ~/path/to/sourcename.tiff
tesseract sourcename.tiff outputname pdf
Like I mentioned before, OCR is slow. Expect to let it munch for a while. It also complains in some places. This seems to happen in places where prior annotation has left interesting shapes or text in the margins. It seem that tesseract establishes layout expectations for the document, then gets nervous where those expectations are not fulfilled.
As-MacBook-Air:Desktop macair$ tesseract sedgwick.tiff sedgwick pdf
Tesseract Open Source OCR Engine v3.03 with Leptonica
Page 1 of 23
OSD: Weak margin (2.79) for 125 blob text block, but using orientation anyway: 0
Page 2 of 23
Page 3 of 23
Page 4 of 23
Page 5 of 23
Page 6 of 23
Page 7 of 23
Page 8 of 23
Page 9 of 23
Error in boxClipToRectangle: box outside rectangle
Error in pixScanForForeground: invalid box
Page 10 of 23
Page 11 of 23
Page 12 of 23
Page 13 of 23
Page 14 of 23
Page 15 of 23
Page 16 of 23
Page 17 of 23
Page 18 of 23
Page 19 of 23
Page 20 of 23
Page 21 of 23
Page 22 of 23
Page 23 of 23
And there you have it. Quick conversion from useless .pdf to useless .tiff, then easy, non-UI conversion from useless .tiff to useful, OCR .pdf. Enjoy.